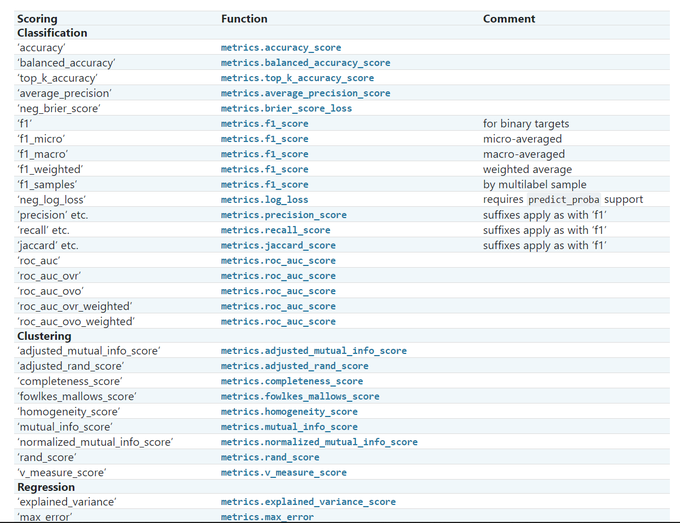
Recall, Precision, and F1 score explained.

Search for a command to run...
No comments yet. Be the first to comment.
A primer on factorials The '!' behind the 0, is notation for something called a 'factorial'. A factorial basically tells you to take the product of all integers and itself before it until you reach 1. If that didn't make any sense, take a look at thi...
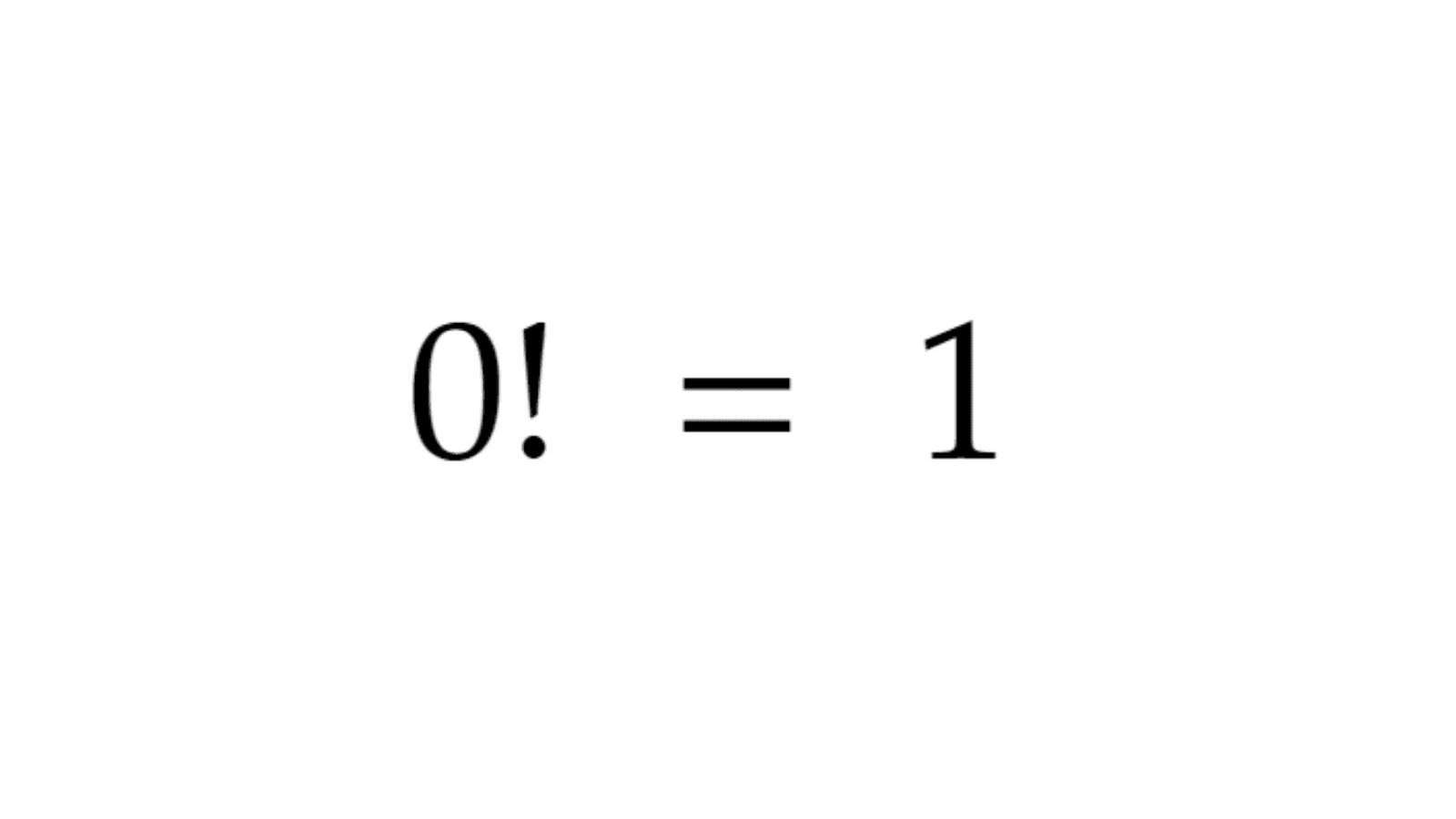
Before we understand how logarithms work, it is important to know how exponents work. aᶜ=b (read as "a to the power of c equals b") is an exponent where a,b and c are numbers. aᶜ=b just means that a multiplied by itself c amount of times is equal to ...

For this simple project we will use OpenCV in Python. It is a library using which we can develop real-time computer vision applications. It mainly focuses on image processing, video capture and analysis including features like face detection and ob...

What you are going to read below is a roadmap for the first 30 days of getting started with machine learning as a complete beginner. If you don't know how to code or anything about what machine learning is, then this blog post is for you. Step 1: Lea...

A store owner recently noticed an alarmingly high rate of shoplifting.
He develops a machine learning model that predicts if a customer has shoplifted or not and it is 95% accurate!
He deploys the model but a month later catches no shoplifters...
Why?
Before we get into this problem it is important to understand what accuracy is.
Accuracy is the number of times you predicted something correctly divided by how many times you actually predicted it.
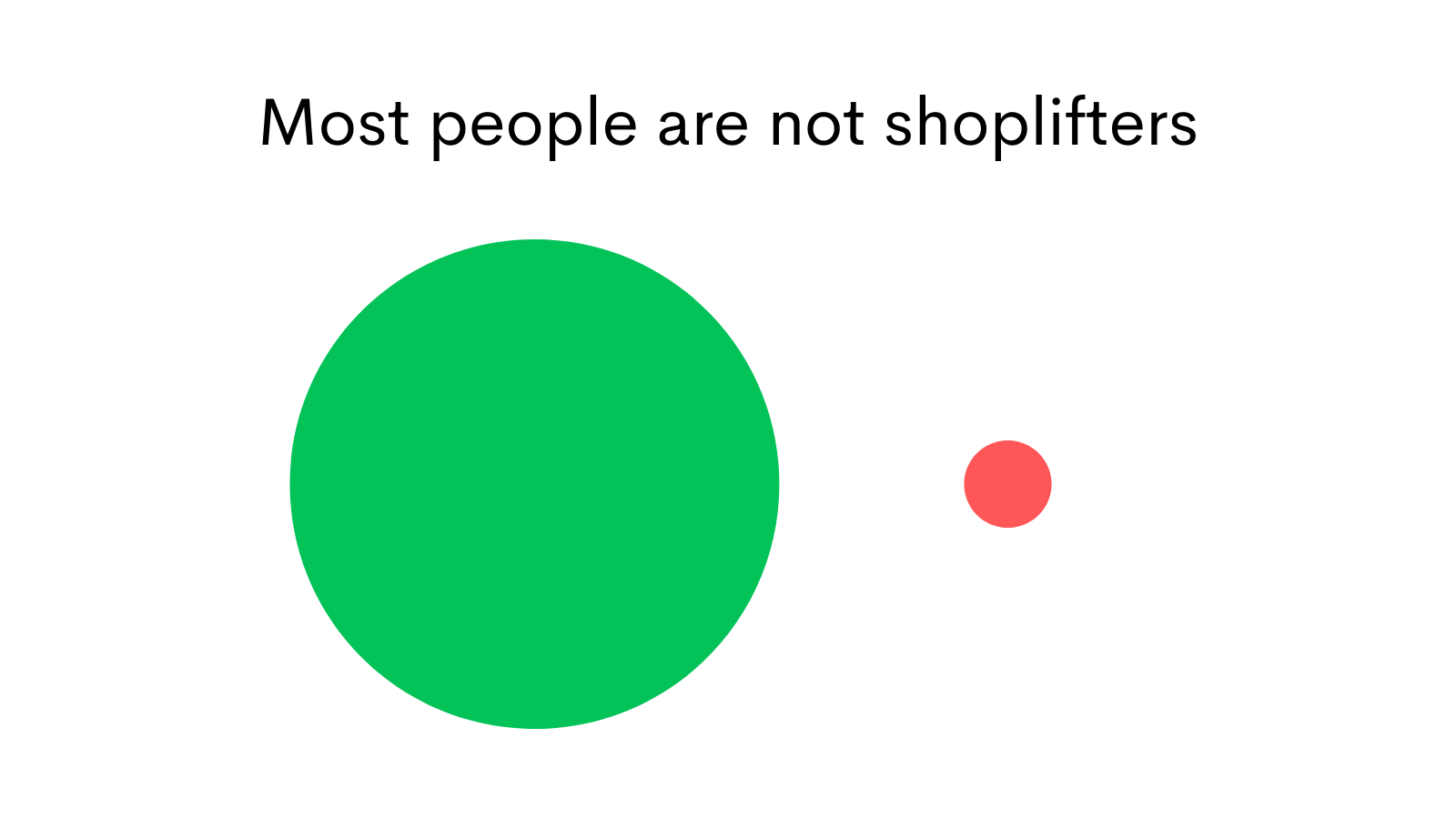
If you closely look at the dataset, you will notice that out of the 10,000 customers that entered the store, only 500 were shoplifters in that month.
Some quick math will tell you that 95% of customers are not shoplifters and the other 5% are.
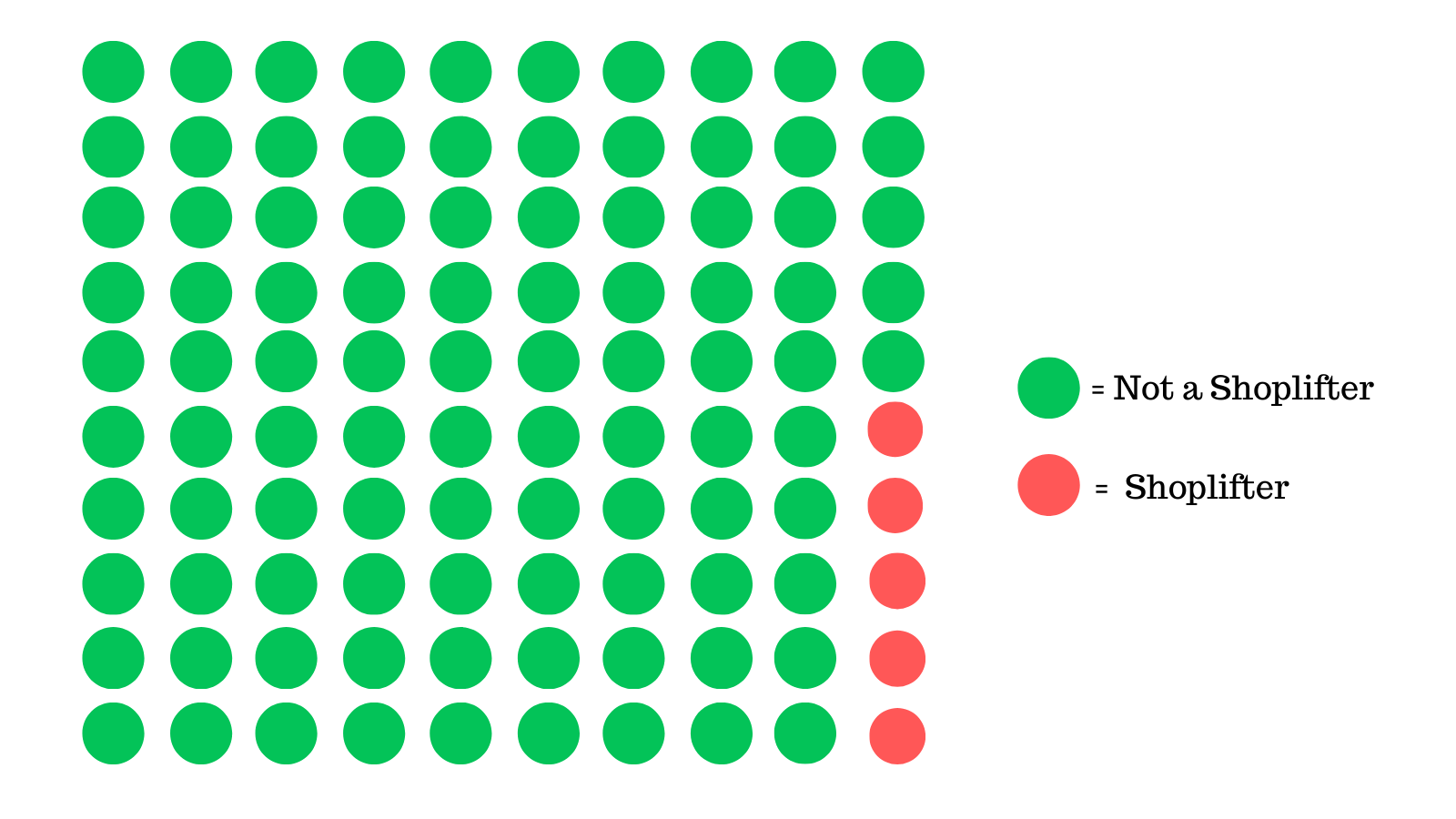
If you basically said that everyone was not a shoplifter, you'd be correct in 95 out of 100 cases, which is what the model did.
You would be wrong in the other 5 cases, but who cares?
We're still 95% accurate, but this is clearly not what we are looking for.
This problem happens in 'imbalanced' datasets where the data is heavily skewed.
You're either a shoplifter, or you're not, and the former is significantly more present in the dataset.
Our model finds a shortcut to increase accuracy.
Then, how do we solve this problem?
Evaluate your model using a different metric, let us take a look at recall and precision, but first, it is important to understand some terminology.
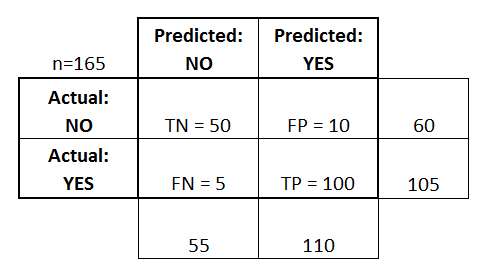
This is a confusion matrix, it shows you all the possible scenarios of the predictions of a model Vs the ground truth.
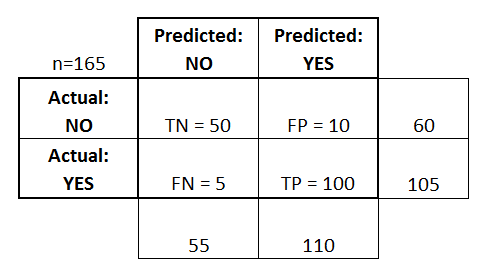 Pretty confusing right?
(No pun intended)
Pretty confusing right?
(No pun intended)
Let me simplify it.
This meme explains is better, the confusion matrix shows us the predictions of a model Vs the ground truth.
Consider the doctor to be the model and the patient to be the ground truth.

Case 1: Our model predicts someone shoplifted when they actually did (TP - True Positive)
Case 2: Our model predicts someone shoplifted when they didn't (FP - False Positive)
Case 3: Our model predicts someone did not shoplift when they did (FN - False Negative)
Case 4: Our model predicts someone did not shoplift when they didn't (TN - True Negative)
Whenever you're confused, just refer to the above meme ;)
In formal terms, 'recall' is defined using this formula.

Or
TP: Shoplifters correctly identified FN: Shoplifters missed
Now if the model classifies no one as a shoplifter, it is going to have 0 recall.
This means it is "not good at all" if we are optimizing to have as high of recall as possible.
On the flip side, what if we label everyone as a shoplifter?
We'll have a recall of 100%, after all, recall just cares about not missing shoplifters, not about false accusations on customers (False Positive).
We basically replace False Negatives with False Positives in the denominator.
Or
By this point, you might've guessed what problem we will encounter if we only optimize for high precision in our model.
The model can just call everyone not a shoplifter and have high precision.
Recall and precision are related such that high precision leads to low recall, and low precision leads to high recall.
We obviously want both to as high as possible, is there any metric that combines both precision and recall?
The F₁ score is the harmonic mean of precision and recall.
The harmonic mean is a special type of mean(average) which is explained by this formula.
We use this mean instead of the normal mean because the normal punishes extreme values.

This translates to our model being able to catch shoplifters and at the same time not falsely accuse innocent customers.
The model will be sure when it catches a shoplifter that it is actually a shoplifter and that brings this story to an end.
Over the next few months, I will be explaining even more evaluation metrics like the F₁ score.
If you enjoy such content, make sure to subscribe to my newsletter .